Sist oppdatert 28.3.2021 kl 04:21
Hans Rosling, Professor i global helse ved Karolinska universitetet i Stockholm, startet en gang en av sine forelesninger med å spørre sine studenter følgende spørsmål:
Hvilket land av de følgende parene, altså som står ved siden av hverandre, har høyest barnedødelighet?
Før du sjekker fasit og leser videre; skriv ned selv hvilke land du tror har høyest barnedødelighet og se hvor mange rette du får!

Da Rosling summerte opp hva alle studentene svarte den dagen fant han ut at de i snitt hadde 1,8 rette svar av fem mulige. Så lot han en gruppe sjimpanser få velge mellom de samme parene. De fikk ganske nøyaktig 2,5 rette i gjennomsnitt, altså halvparten rett. Betyr dette at svenske sjimpanser vet mer om verdenshelse og barnedødelighet enn svenske studenter? Du vet ganske sikkert mye om verden allerede og slik spørsmålet over ble formulert er du nok ganske sikker på at en sjimpanse ikke vet mer om barnedødelighet enn en legestudent. Sjimpansene valgte rett og slett tilfeldig og over tid betyr det at de i snitt vil få 2,5 rette. Det er omtrent som å kaste en mynt i luften og fange den på håndleddet, den vil lande like ofte på begge sider. Det dette lille eksperimentet forteller oss er at mennesker gjør mer enn å bare gjette. Vi tar utgangspunkt i det vi vet fra før når vi skal ta en avgjørelse om noe. Det er lett å tenke at Malaysia som ligger i Sør-Øst Asia, et land som ikke får like mye oppmerksomhet i media i Norge som Russland, sannsynligvis har dårligere helseforhold enn store mektige Russland, vår egen nabo. Men i følge FN så har Russland en dobbelt så høy barnedødelighet (12 av 1000 fødte) som Malaysia (6 av 1000 fødte), på tross av at de har flere helsearbeidere per innbygger enn de fleste europeiske land (Kilde: FN). Vi baserer altså mye av vår forståelse og vårt syn på verden på hva vi tror vi vet om den, ikke nødvendigvis hvordan den faktisk er. Dette eksemplet er i utgangspunktet ganske uskyldig, men hva hvis man er sitter på Stortingets utenriks- og forsvarskomite og skal være med på å bestemme hvor norske bistandspenger skal gå? Selv politikere kan ta avgjørelser basert på sine fordommer og antagelser om hvordan forskjellige deler av samfunnet er. Men det betyr ikke at det er spesielt lurt. For de aller fleste vil det alltid være en fordel å forstå verden i størst grad slik den virkelig er, og ikke slik man tror den er. Det er dette samfunnsvitenskapene forsøker å hjelpe ikke bare politikere med, men oss alle. For er det noe som er sikkert så er det at vi alle opplever og forstår verden litt forskjellig; Din virkelighet er ikke min virkelighet. Vitenskapen forsøker å forstå verden slik den faktisk er så godt som mulig uten å la seg påvirke av følelsene, opplevelsene, holdningene og verdiene til den som utfører undersøkelsen. Veldig mye av hva vi kanskje tenker på som sunn fornuft er kanskje ikke så åpenbart som det vi tror. Gifter egentlig folk seg fordi de elsker hverandre? Har menn en annerledes atferd enn kvinner fordi man født forskjellige? Har vi full likestilling i Norge? Dette er typiske sosiologiske spørsmål som vi kan søke større innsikt i gjennom bruk av vitenskapelige fremgangsmåter, metoder. Forskningsresultater som svarer på akkurat slike spørsmål dukker daglig opp i media. Som i eksemplet med studentene fra Stockholm oppgis forskningsresultatene ofte som statistiske tall med klare og tydelig konklusjoner. Men tradisjonelle massemedier presenterer ikke alltid resultatene slik som de egentlig burde. Noen ganger forenkler de resultatene sterkt, mens andre ganger har ikke journalisten selv forstått tallene og rapportert de helt feil. Samfunnsvitenskaper som statsvitenskap, sosiologi og sosialantropologi ønsker alle å forstå og beskrive verden slik den er for å kunne forutsi hvordan den vil utvikle seg, kritisere noe eller for å forsøke å endre noe ved den. For å kunne gjøre dette må forskeren sette sine egne verdier, holdninger, meninger og tidligere opplevelser til side for å tilstrebe objektivitet og nøytralitet.
Hva er sant?

I hverdagslige diskusjoner og samtaler beskriver vi som regel samfunnet slik vi ser den ut i fra hva vi kan om den, hvilke opplevelser vi har hatt og hvordan vi tolker alt dette. Dette kaller vi en subjektiv oppfatning av samfunnet. En forsker må derimot tilstrebe å beskrive samfunnet objektivt. En objektiv beskrivelse av et samfunn vil si å forklare det slik det faktisk er, uavhengig av hvem den undersøker eller hvem som gjennomfører undersøkelsen. For å skaffe slik kunnskap benytter forskeren en eller flere fremgangsmåter for å samle inn informasjon, data, om samfunnet som han deretter analyserer. Metodene som forskerne benytter inneholder regler og fremgangsmåter som er der for å sikre at forskeren kommer frem til mest mulig sannferdige resultater, altså resultater som stemmer mest mulig opp mot hva er virkelig, eller hva som er sant om du vil. Arbeidet skal beskrives og rapporteres grundig slik at andre forskere kan gå igjennom de og gjenta undersøkelsen helt likt for å se om førstemann har fulgt reglene. God forskning vil alltid bli gått nøye i sømmene av andre forskere. En viktig ting å se etter når man skal bruke forskningsresultater til å forklare eller påvirke samfunnet er om de tar hensyn til alle tenkbare forklaringer. For eksempel: Hva kan forklare at en bestemt klasse får en hel karakter i snitt bedre på en matteprøve enn de andre klassene på den samme skolen? Er elevene smartere? Er de flittigere og mer hardtarbeidende enn de andre? Er læreren snillere på karakterene eller var prøven lettere? Er læreren flinkere enn de andre lærerne? Eller kanskje det bare er en ren tilfeldighet? Alt dette må sjekkes mot hverandre før man kan konkludere med det ene eller det andre. Vi kaller dette forklaringsmangfold. Hvis det viser seg at det er en ren tilfeldighet at klassen gjorde det bedre enn de andre vil det være veldig urettferdig overfor læreren hvis man hadde anklaget henne for å være snillere med karakterene. I vitenskapen leter vi alltid etter det som kan motbevise våre egne ideer om hva som er virkelig. Vi forsøker heller å avkrefte våre fordommer enn å bekrefte de, for det er lett å se sammenhenger som egentlig ikke er der hvis vi ønsker å se de. Når vi har en antagelse om en sammenheng mellom to forskjellige sosiale fenomener, slik som for eksempel karakterer og hard studieinnsats fra elevene, så forsøker vi å se om vi kan bekrefte det motsatte, at det ikke er en sammenheng. Dette kaller vi den hypotetisk-deduktive metode.
Noen grunnleggende begreper
Noen begreper går igjen i samfunnsvitenskapene. De brukes for å gjøre det lettere å analysere resultatene våre.
 Enheter er hvem eller hva vi ønsker å studere. Hvis vi ønsker å få innsikt i læreres prestasjoner i forhold til deres utdannning så er enhetene vi undersøker lærerne.
Enheter er hvem eller hva vi ønsker å studere. Hvis vi ønsker å få innsikt i læreres prestasjoner i forhold til deres utdannning så er enhetene vi undersøker lærerne.
Variabler er egenskaper ved enhetene vi undersøker som varierer, slik som for eksempel lærernes (enhetene) utdanningslengde og deres prestasjoner.
Utdanningslengde og prestasjoner er ganske vage begreper, de kan ikke måles med ja eller nei, men vi må operasjonalisere dem, altså gjøre de målbare. Utdanningslengde kan måles i år eller i grader som bachelor, master og doktorgrad. Lærerens prestasjoner kan være vanskeligere å operasjonalisere og vi må se etter eventuelle feilkilder før vi bestemmer oss for hva vi skal bruke. Hvis vi måler lærerens prestasjoner ut i fra standpunktkarakterer så er det en risiko for at disse er påvirket av lærerens subjektive vurderinger; de kan være for snille eller for strenge for alt vi vet. Hvis vi skal bruke elevenes karakterer vil det da være bedre å bruke eksamensresultater hvor prøvene er rettet av andre. Kan du komme på andre måter å operasjonalisere en lærers prestasjoner på?
Før vi begynner innsamlingen av data må vi formulere en hypotese. En hypotese er en antagelse om hvordan virkeligheten er, for eksempel en mulig forklaring på noe vi har observert eller en forutsigelse om noe nytt basert på tidligere observasjoner. Vi formulerer som regel hypotesene våre som en antagelse om en sammenheng mellom to fenomener. «Lærere med høy utdanning har bedre effekt på læring enn lærere med lav utdanning.» Høy og lav utdanning kan operasjonaliseres med for eksempel mer eller mindre enn tre års utdanning, mens effekt på læring kan operasjonaliseres med karaktergjennomsnittene til lærerens elever. En hypotese er én antagelse om en sammenheng, men når flere hypoteser kan brukes til å forklare hverandre så kaller vi det en teori. En teori er altså et sett av hypoteser som forklarer og bekrefter hverandre ved testing. En teori er altså så nært vi kan komme en samfunnsvitenskapelig sannhet. Siden vitenskapen aldri helt kan motbevise en påstand, bare usannsynliggjøre den, så har vi ingen rene sannheter i sosiologi og sosialantropologi. Det nærmeste vi kommer er kanskje Eilert Sundts lov om at antall giftermål på ett tidspunkt vil variere med antall fødsler på et tidligere tidspunkt. Enkelt sagt; hvis det fødes få barn i ett kull, for eksempel på grunn av en hungersnød eller krig, så vil det være færre som gifter seg når dette kuller vokser opp enn det var i kullet før.
 Når vi har bestemt oss for hva vi ønsker å vite mer om, hvem vi ønsker å vite mer om og har operasjonalisert variablene slik at de kan måles, må vi velge forskningsobjekter, altså hvem vi ønsker å spørre. Noen ganger er det enkleste å ta med seg spørsmålene ut på gata eller på gangen på skolen og stoppe første og beste person som går forbi. Andre ganger bør vi kanskje velge de vi vil snakke med selv på forhånd, for eksempel hvis vi skal foreta et intervju som tar mer enn en time å gjennomføre. Hvis vi ønsker å undersøke lærernes prestasjoner vil det ikke være praktisk å spørre alle lærerne i landet om deres utdanning og sjekke dette opp mot resultatene til alle elevene i klassene deres. Vi kaller alle lærerne i landet for populasjonen. En populasjon er summen av alle mennneskene som faller inn under den kategorien vi ønsker å undersøke. Men for å spare tid og penger kan vi ikke spørre absolutt alle lærerne om det vi ønsker, i stedet gjør vi et utvalg. Utvalget velges slik at vi kan være mest mulig trygge på at de representerer hele populasjonen. Dette kaller vi et representativt utvalg.
Når vi har bestemt oss for hva vi ønsker å vite mer om, hvem vi ønsker å vite mer om og har operasjonalisert variablene slik at de kan måles, må vi velge forskningsobjekter, altså hvem vi ønsker å spørre. Noen ganger er det enkleste å ta med seg spørsmålene ut på gata eller på gangen på skolen og stoppe første og beste person som går forbi. Andre ganger bør vi kanskje velge de vi vil snakke med selv på forhånd, for eksempel hvis vi skal foreta et intervju som tar mer enn en time å gjennomføre. Hvis vi ønsker å undersøke lærernes prestasjoner vil det ikke være praktisk å spørre alle lærerne i landet om deres utdanning og sjekke dette opp mot resultatene til alle elevene i klassene deres. Vi kaller alle lærerne i landet for populasjonen. En populasjon er summen av alle mennneskene som faller inn under den kategorien vi ønsker å undersøke. Men for å spare tid og penger kan vi ikke spørre absolutt alle lærerne om det vi ønsker, i stedet gjør vi et utvalg. Utvalget velges slik at vi kan være mest mulig trygge på at de representerer hele populasjonen. Dette kaller vi et representativt utvalg.

Når vi skal undersøke forskjellige variabler på en stor populasjon velger vi altså bare å spørre noen av dem. For å sikre oss at vi får resultater som ligner mest mulig på de vi ville fått om vi spurte alle må vi plukke personene, enhetene, ut systematisk. En vanlig metode er å gjøre et sannsynlighetsutvalg hvor enhetene plukkes ut helt tilfeldig, for eksempel ved loddtrekning eller ved terningkast. Utvalget kan også foregå mer systematisk ved å plukke ut hver femte på en liste slik som telefonkatalogen eller velge alle enhetene på forskjellige geografiske steder. Ikke-sannsynlighetsutvalg er en annen måte å plukke ut enheter på. Vi kan plukke ut enheter basert på vårt eget skjønn av hvem vi mener kan ha de beste svarene eller vi kan la enhetene komme til oss. Det siste er noe som gjøres hver eneste dag på nettet når aviser, butikker, studenter og forskere legger ut sine spørreskjemaer på nettet. Vi ser daglig artikler på nett med spørsmål som «Bør Norge fortsatt være medlem av EØS-avtalen?» hvor man kan velge mellom for eksempel «Ja», «Nei» eller «aner ikke». Ulempen her er at det som regel er de som allerede er mest interessert som svarer. Vi får altså et skjevt utvalg, et utvalg som ikke kan brukes til å forklare eller forstå hele samfunnet. Dette er særlig synlig når det spørres om kontroversielle ting som trygdemisbruk, kriminalitet og normer og verdier.
Forskningsprosessen

Metode
Det er mange fremgangsmåter vi kan benytte for å skaffe oss kunnskaper om virkeligheten og vi skiller mellom to hovedmetoder, nemlig kvantitativ og kvalitativ metode. Kvantitativ metode egner seg best når man ønsker å sette seg inn i atferdsmønstre i større grupper eller hele samfunn. De brukes ofte til å forklare gruppers atferd og rollemønstre, mens kvalitativ metode brukes for å gå dypt inn i mindre gruppers forståelse av verden. Kort sagt; kvantitative metoder brukes når man ønsker å undersøke mange enheter på få variabler for å få en generell forståelse av manges atferd, mens kvalitative metoder brukes for å undersøke få enheter på mange variabler for å få en dypere forståelse av noen få.
Kvalitativ metode
Kvalitative metoder benytter seg hovedsakelig av forskerens egen evne til å observere og tolke det som skjer rundt ham i det det skjer. Forskeren plasserer seg selv inn i situasjonen han ønsker å forske på og bruker sine egne sanser og sin egen evne til å leve seg inn i og forstå for å på den måten oppdage mønstrene i livene til de han observerer. De kvalitative metodene egner seg best hvor det ikke er så alt for mange mennesker som skal observeres og hvor man ønsker å vite mer om hvilken mening eller betydning forskjellige hendelser, erfaringer har og hva som motiverer individer til handling. Det er derfor også en metode som er vanligere blant sosialantropologer som gjerne utforsker mindre samfunn eller grupper av mennesker enn det sosiologer som oftere søker kunnskap som i større grad gjelder hele storsamfunnet eller hele befolkninger. Det man lærer gjennom kvalitativ forskning kalles gjerne myke data fordi de er basert på hva den enkelte forsker har sett og opplevd selv og hvordan han eller hun da har tolket dette personlig. Utfordringen med denne metoden er da også nettopp forskerens personlige egenskaper og evne til å både sette seg inn i og kunne empatisere med de han søker kunnskap om samtidig som han ikke må bli så knyttet og bundet til menneskene at hans tolkninger blir farget av hans følelser for menneskene. Det er flere måter å observere mennesker i sine daglige liv på som forsker og de har forskjellige utfordringer med seg, ikke bare faglig, men også etisk. Det vanligste er såkalt åpen observasjon. Dette har kanskje flere av dere opplevd selv allerede i klasserommet. Det er slett ikke uvanlig at lærerstudenter eller forskere fra universitetet sitter og observerer i et klasserom. Studentene gjør det for å se hvordan lærer-elev-forholdet kanskje oppleves utenfra, eller kanskje som et lite forskningsprosjekt i forbindelse med en masteroppgave, men målet er det samme som forskerne; å forstå hvordan noe virker. Læreren presenterer de gjerne for elevene, og deretter fortsetter undervisningen som vanlig. Hvis ikke læreren presenterer forskeren så er det uansett sannsynlig at spørsmålet vil dukke opp ganske raskt, en student eller en voksen forsker skiller seg alltid litt ut fra den vanlige elevmassen. Det virker ganske enkelt og rett frem å skulle observere noen på denne måten, men kan man egentlig stole helt på hva man ser? Alle lærerstudenter har opplevd å bli observert når de har undervist en klasse i en praksisperiode ute i skolen. Det tar litt tid før man venner seg til å ha noen i bakgrunnen som man vet bare har en jobb å gjøre; nemlig å følge med på hver eneste lille ting du foretar deg. Og det påvirker måten du fremstår på og hvordan du forholder deg til klassen, i hvert fall i begynnelsen. Det er også utfordringen for alle forskere som ønsker å gjennomføre åpen observasjon av en gruppe. Dette leder oss inn på neste metode; skjult observasjon. Skjult observasjon skjer når forskeren sitter utenfor en gruppe og observerer den uten at deltakerne i gruppen er klar over at de blir observert, for eksempel en forsker som sitter i hjørnet på en kafé og studerer kundenes atferd i køen foran kassen. Det er flere problemer med skjult observasjon. For det første så vil ikke forskeren kunne gjøre notater eller filme de han ønsker å observere uten å avsløre seg selv og for det andre så kan man aldri helt vite om han ikke påvirker atferden til de han ønsker å undersøke bare ved å være tilstede. En svært attraktiv forsker vil for eksempel tiltrekke seg oppmerksomhet fra det motsatte kjønn og dermed påvirke hvordan disse oppfører seg. Deltakende observasjon er en metode som ofte benyttes av sosialantropologer som undersøker små samfunn eller kulturer som de ønsker å forstå bedre. Det sier seg selv at en norsk sosialantropolog ikke vil kunne gå i ett med brasilianske yanomamii-indianere i Amazonas-jungelen. En rekke kulturelle forskjeller som språk og utseende vil skille vedkommende for mye ut fra befolkningen til at man kan gå for å være en av de, men hvis man er så heldig å bli invitert inn i indianerstammen så kan man leve sammen med de og over tid lære deres kulturelle og sosiale vaner å kjenne. Problemet med deltakende observasjon er derimot ganske åpenbart; forskeren deltar og påvirker dermed undersøkelsespersonenes atferd gjennom ikke bare være tilstede, men også være en del av gruppen han ønsker å undersøke. Skjult deltakende observasjon har vært benyttet en rekke ganger av både sosialantropologer og journalister som ønsker en indre innsikt i subkulturer og parallellsamfunn slik som kriminelle miljøer, ytterliggående politiske miljøer og religiøse minoriteter og sekter. Dette har gitt både spennende og skremmende innsikter i blant annet hvordan deres sosiale bånd styrkes og bygges opp, hvordan makt fordeles innad, eller fokuseres på noen få i gruppen og hvordan sosiale strukturer og bånd opprettes og vedlikeholdes. Men det er også en metode som brukes ekstremt sjelden da det innebærer en rekke både vitenskapelige og etiske problemstillinger. Ikke bare må man presentere seg som både noe og noen man ikke er, men man må også delta på lik linje som alle de andre i gruppen. Man risikerer både å påvirke medlemmenes daglige atferd gjennom ubevisst å spre sine personlige holdninger og verdier, men man kan også måtte risikere å gjøre handlinger som strider mot ens egen overbevisning, samvittighet eller, i verstefall, bryter med loven.
I den norsk-svenske filmen «Salmer fra kjøkkenet» fra 2003 får vi følge forskere fra det svenske Hemmens Forskningsinstitut som utforsker atferdsmønstrene til en rekke norske, single, menn på landsbygda i etterkrigstidens Norge. Mer spesifikt; på kjøkkenet, mens de utfører det de anser som husmoroppgaver. Videoen over er et godt eksempel på hvordan selv den mest forsiktige observasjon fra en forsker kan påvirke miljøet han søker kunnskap om. På godt og, i dette tilfellet, veldig ubehagelig.
Det kvalitative forskningsintervjuet er en velbrukt metode hvor man i stedet for å stille lukkede spørsmål hvor den som intervjues må velge blant et sett forutbestemte svaralternativer stiller seg åpen og lyttende ovenfor det nye og kanskje uventede. Intervjuet er en tidkrevende form for forskning, men det er nyttig når man ønsker å få en dypere forståelse for et bestemt fenomen, for eksempel hvordan mennesker opplever noe og hvilken mening de legger i det. Vi kan gjøre et halvstrukturert intervju hvor forskeren på forhånd har bestemt et sett temaer, men kun laget åpne spørsmål for å lede forskningsobjektet inn i en generell retning. Spørsmålene er skrevet ned som en guide for intervjuet, men det er ingen bestemt rekkefølge på de og man tar seg den tiden man trenger til å gå dypt inn i temaene fremfor å svare kort og overfladisk. Det er også mulig å gjøre et ustrukturert intervju hvor man ikke benytter noen form for intervjuguide eller ferdigformulerte spørsmål. Dette er mer som en generell samtale som gjerne kan brukes for å utvikle ideer og skaffe et innblikk i et fenomen eller en sosial gruppe man ikke kjenner fra før av. Valget av intervjuobjekt, altså hvem man intervjuer, er ofte avgjørende for å få gode resultater. Når temaet for intervjuet omhandler et bestemt fagområde eller interesseområde er det en fordel å finne personer man kan være noenlunde sikker på at besitter informasjon man kan være interessert i. Samtidig er det viktig å ikke utelukke noen helt heller, man vet aldri hvem som sitter på nye og spennende innsikter.
Ofte benyttes kvalitativ metode som en forundersøkelser for å få oversikt over det man ønsker å lære mer om før man gjennomfører en større undersøkelse, som for eksempel en spørreundersøkelse på et stort antall mennesker. På den måten får man en bedre innsikt i hva man bør spørre om slik at man ikke i ettertid oppdager små, men kanskje viktige ting man har glemt å spørre om.
Kvantitativ metode
Med kvantitativ metode forsøker vi å forstå sosiale fenomener gjennom å telle og måle de for så å bruke statistiske verktøy for å analysere og tolke dem. Statistikk hjelper oss å se verden for det den er og lar oss oppdage sammenhenger og fenomener som skjuler seg bak vår atferd. Vi bruker statistikk hver eneste dag og vi lar store deler av livene våre styres av tallenes makt. Den norske staten har sitt eget statistikkbyrå i Statistisk Sentralbyrå (SSB) som har vitenskapelig ansatte som hver eneste dag spør og graver og regner og analyserer på alt fra hvor gamle vi i gjennomsnitt blir, hvor mye et skolebarn koster å undervise i året til å lage prognoser for hvor godt eller dårlig det vil gå med norsk industri og handel fremover. Disse tallene brukes av politikere og interessegrupper til å styrke sine egne argumenter eller svekke andres, ofte avslører de skjulte feil og mangler ved samfunnet som fører til at hele grupper ikke får oppfylt de rettighetene de har eller kanskje de viser skjevheter i fordelingen som gir noen grupper mer makt eller goder de ikke har krav på. Storting og regjering bruker derfor tall fra SSB blant annet til å ta bedre avgjørelser om for eksempel fordelingen av samfunnets goder og håndhevelsen av våre sosiale normer og etiske forpliktelser til hverandre.
Brukt riktig forbedrer de ikke bare våre liv, helse og sosiale samliv, men de gir oss innsikt i andre samfunn, kulturer og ikke minst andre menneskers atferd. Brukt feil kan de lede oss til å ta feilaktige og skadelige avgjørelser for oss selv og andre. Vi har hatt folketellinger av forskjellig art i Norge siden midten av 1700-tallet. Den gang var det for å få en oversikt over landets ressurser og ikke minst; våpenføre menn. Senere har folketellingene fått flere variabler slik som kjønn, sivilstatus, barn, yrke, bosted, formue og så videre. Men ingen har vært mer skadelige enn enkle spørsmål som trosretning og etnisitet. På bakgrunn av gamle folketellinger satte Nasjonal Samling i gang grundige spørreundersøkelser av norske jøder i 1942. Like etterpå ble halvparten av de norske jødene deportert til nazistenes konsentrasjonsleirer på kontinentet, delvis utvalgt på bakgrunn av undersøkelsen. Å spørre om etnisitet, seksuell legning og andre veldig personlige ting er derfor underlagt strenge restriksjoner som for eksempel krav om anonymisering i dag. I tillegg må man søke om tillatelse fra myndighetene og man må undertegne en kontrakt med en kontaktperson på hvordan man oppbevarer det man har samlet inn mens man jobber med undersøkelsen og ikke minst hvordan de oppbevares etterpå. Kanskje må man makulere alle spørreskjemaer og navnelister slik at ingen andre kan få tak i informasjonen etterpå. Dette er i hvert fall veldig vanlig ved kvalitative intervjuer hvor intervjuobjektet anonymiseres. Ofte er variabler som dette viktige deler av det vi ønsker å forske på og kanskje ganske uskyldig i seg selv, men risikoen for at noen kan misbruke tallene våre vil alltid være der, og derfor må vi også være strenge med hvordan vi lagrer og behandler slik informasjon. Det er ikke sjelden man ser at journalister tolker vitenskapelige rapporter feil eller misforstår tall fra for eksempel Statistisk Sentralbyrå. Det kan med letthet argumenteres for at alle burde kurses grundigere i grunnleggende statistisk og vitenskapelig metode på skolen.
Innsamling og analyse
Mål for middelverdi
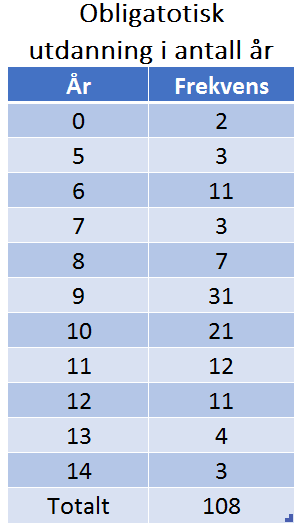
Noe av det første vi gjerne ser etter når vi skal analysere en variabel er hva som er mest typisk for den. Når vi leser i avisene om resultatene fra de nasjonale prøvene er det gjennomsnittsresultatene til den enkelte skole, kommune eller fylke vi som regel ser oppgitt. I undersøkelser med mange enheter er også gjennomsnitt et veldig nyttig verktøy. Gjennomsnittet kan for eksempel hjelpe oss å sammenligne utvikling over tid. Det kan både hjelpe oss å finne de skolene som har en positiv utvikling slik at vi kan undersøke dem for hva de gjør riktig og se om vi kan overføre den kunnskapen på skoler som gjør det dårligere. Gjennomsnitt er som vi vet summen av alle verdiene delt på antall enheter, men det er ikke alltid dette er den beste måten å regne gjennomsnittet på, særlig hvis det er noen få enheter som avviker sterkt fra gjennomsnittet, derfor har vi flere mål for middelverdi som vi ofte må ty til i tillegg for å få et mer korrekt bilde av virkeligheten; modus og median. I tabellen til høyre ser du en oversikt over 108 land etter antall obligatoriske skoleår. Kolonnen til venstre viser utdanning i antall år, variabelen, og kolonnen til høyre viser antall land, altså enheter, som har like lang obligatorisk skole som verdien på variabelen tilsier (Kilde FN-statistikk 2011).
Gjennomsnitt: For å finne gjennomsnittet tar vi summen av verdiene på variabelen, i dette tilfellet er det antall år med utdanning; 1005 år, og deler på antall enheter, her antall land; 108: 
Median: Hvis vi rangerer alle enhetene ut fra verdien på variabelen deres fra lavest til høyest så er median verdien på den midterste enheten. Hvis vi vil finne medianen til antall år obligatorisk skole raskt så må vi finne ut hvilken enhet som er i midten og det gjør vi ved å ta antall enheter (n) + 1 og dele på 2.
 I vårt tilfelle blir summen et oddetall, da blir medianen en verdi i mellom enhet 54 og 55. Begge enhetene våre her har verdi 9, men hvis de ikke hadde hatt det ville vi bare tatt gjennomsnittet av de to verdiene.
I vårt tilfelle blir summen et oddetall, da blir medianen en verdi i mellom enhet 54 og 55. Begge enhetene våre her har verdi 9, men hvis de ikke hadde hatt det ville vi bare tatt gjennomsnittet av de to verdiene.

Modus forteller oss enkelt og greit bare hvilken verdi som det er flest av. I frekvenstabellen kan vi se at dette er 9, noe vi lett kan se om vi setter opp et stolpediagram.
![]()
Spørreskjemaer – lukkede spørsmål – strukturerte skjemaer – noen tips
Når innsamlingen er ferdig gjenstår det virkelig store arbeidet, nemlig å registrere og analysere alt som er samlet inn. Hvordan vi analyserer resultatene avhenger av våre hypoteser. Den enkleste og vanligste analysen er å finne forskjellige middelverdier slik som gjennomsnitt. Leter vi etter sammenhenger mellom forskjellige fenomener som for eksempel om det er en sammenheng mellom karakter og tilgang til Facebook på skolen må vi sette opp frekvens- og krysstabeller som kan gi oss innsikt i om de forskjellige variablene overlapper hverandre nok til å svekke eller styrke antagelsene våre. Vi bruker som regel egnede dataprogrammer for å gjøre de største beregningene for oss, særlig når det er snakk om mange variabler og enheter da det kan fort bli enormt mye å holde orden på. For mindre spørreundersøkelser er det ingenting i veien for å bruke enklere regneark slik som Excel for gjøre våre beregninger. La oss nå si at vi har gjennomført en enkel spørreundersøkelse på en samfunnsfagklasse på en norsk videregående skole hvor vi har spurt om nettopp forholdet mellom bruk av sosiale medier i undervisningstimene og karakternivået. Undersøkelsen er gjort anonymt gjennom lærerens It’s learning-konto for at ingen skal føle seg uthengt eller mobbet i ettertid. Vi vet at å spørre bare en klasse ikke er nok for å kunne generalisere innholdet, altså bruke det til å beskrive alle samfunnsfagelever i hele landet, men det kan gi oss et inntrykk av hvordan det står til på skolen og for en forsker ville en slik undersøkelse kunne brukes som en forundersøkelse til et større prosjekt.
 Enheter: Elever Populasjon: Skolen (ca. 600 elever) Utvalg: en klasse på 20 elever. Hypotese: Elever som ikke bruker sosiale medier i samfunnsfagstimene presterer bedre enn elever som bruker det. Operasjonalisering: Her kunne vi spurt etter de forskjellige sosiale mediene, slik som Facebook, Twitter, Tumblr og så videre, men siden vi har et så lite utvalg nøyer vi oss med ja og nei. Vi kunne også lagt inn en variabel for hvor ofte og lenge man brukte sosiale medier i undervisningen, men vi nøyer oss med å spørre om de klikker seg innom hver annen time eller oftere. Prestasjonsnivået kan operasjonaliseres som den faktiske standpunktkarakteren den enkelte elev fikk ved siste termin eller vi kan forenkle det ved å si dårligere enn karakter fire for et lavt prestasjonsnivå og lik eller bedre enn karakter fire for et høyt prestasjonsnivå. For enkelhetsskyld gjør vi det sistnevnte nå, altså. Når spørsmålene er formulert (se illustrasjon) gir vi svaralternativene, altså verdiene, en tallkode. For spørsmål 1 blir «Ja» 1 og «Nei 2», mens for spørsmål to sier vi at «Fire eller bedre» er 1 og «Under fire» er 2. Å kode svarene på denne måten er mest praktisk når vi har mange verdier per variabel, slik som for eksempel yrke eller alder, samt at det blir lettere å sette det inn i tabeller på en datamaskin.
Enheter: Elever Populasjon: Skolen (ca. 600 elever) Utvalg: en klasse på 20 elever. Hypotese: Elever som ikke bruker sosiale medier i samfunnsfagstimene presterer bedre enn elever som bruker det. Operasjonalisering: Her kunne vi spurt etter de forskjellige sosiale mediene, slik som Facebook, Twitter, Tumblr og så videre, men siden vi har et så lite utvalg nøyer vi oss med ja og nei. Vi kunne også lagt inn en variabel for hvor ofte og lenge man brukte sosiale medier i undervisningen, men vi nøyer oss med å spørre om de klikker seg innom hver annen time eller oftere. Prestasjonsnivået kan operasjonaliseres som den faktiske standpunktkarakteren den enkelte elev fikk ved siste termin eller vi kan forenkle det ved å si dårligere enn karakter fire for et lavt prestasjonsnivå og lik eller bedre enn karakter fire for et høyt prestasjonsnivå. For enkelhetsskyld gjør vi det sistnevnte nå, altså. Når spørsmålene er formulert (se illustrasjon) gir vi svaralternativene, altså verdiene, en tallkode. For spørsmål 1 blir «Ja» 1 og «Nei 2», mens for spørsmål to sier vi at «Fire eller bedre» er 1 og «Under fire» er 2. Å kode svarene på denne måten er mest praktisk når vi har mange verdier per variabel, slik som for eksempel yrke eller alder, samt at det blir lettere å sette det inn i tabeller på en datamaskin.
 Når vi så har gjennomført og samlet inn igjen spørreskjemaene, eller i dette tilfellet; når alle har besvart undersøkelsen på It’s learning, så samler vi opp tallene og setter de opp i en frekvenstabell for full oversikt. Vi gjør akkurat slik vi gjorde i eksemplet over hvor vi så på middelverdier, men siden vi har to variabler fører vi opp svarene til hver enhet på begge variablene ved siden av hverandre. Slik kan vi raskt se at elev nummer en svarte ja, jeg bruker sosiale medier i timen og at den samme eleven har under fire i standpunkt. Denne tabellen alene sier oss ikke så veldig mye, men vi kan bruke tallene her til å lage en krysstabell. Hypotesen vår sier noe om årsak og virkning; bruk av sosiale medier i timen påvirker prestasjonene i faget. Våre prestasjoner er altså avhengig av variabelen bruk av sosiale medier. Variabelen som er avhengig av den andre setter vi alltid til venstre i krysstabellen.
Når vi så har gjennomført og samlet inn igjen spørreskjemaene, eller i dette tilfellet; når alle har besvart undersøkelsen på It’s learning, så samler vi opp tallene og setter de opp i en frekvenstabell for full oversikt. Vi gjør akkurat slik vi gjorde i eksemplet over hvor vi så på middelverdier, men siden vi har to variabler fører vi opp svarene til hver enhet på begge variablene ved siden av hverandre. Slik kan vi raskt se at elev nummer en svarte ja, jeg bruker sosiale medier i timen og at den samme eleven har under fire i standpunkt. Denne tabellen alene sier oss ikke så veldig mye, men vi kan bruke tallene her til å lage en krysstabell. Hypotesen vår sier noe om årsak og virkning; bruk av sosiale medier i timen påvirker prestasjonene i faget. Våre prestasjoner er altså avhengig av variabelen bruk av sosiale medier. Variabelen som er avhengig av den andre setter vi alltid til venstre i krysstabellen.
 For å fylle krysstabellen så teller vi opp hvor mange i frekvenstabellen som svarte kombinasjonene 1-1 (3 stk), 1-2 (7 stk), 2-1 (8 stk) og 2-2 (2 stk). For å gjøre resultatene mer lettleste prosentuerer vi (se den nederste versjonen av krysstabellen). Nå kan vi se om undersøkelsen vår stemmer med hypotesen:
For å fylle krysstabellen så teller vi opp hvor mange i frekvenstabellen som svarte kombinasjonene 1-1 (3 stk), 1-2 (7 stk), 2-1 (8 stk) og 2-2 (2 stk). For å gjøre resultatene mer lettleste prosentuerer vi (se den nederste versjonen av krysstabellen). Nå kan vi se om undersøkelsen vår stemmer med hypotesen:
Hypotesen vår var: Elever som ikke bruker sosiale medier i samfunnsfagstimene presterer bedre enn elever som bruker det.
Vi ser at 77,8% av de som ikke bruker sosiale medier i samfunnsfagtimene får karakter fire eller bedre, mens av de som bruker sosiale medier i timene får bare 22,2% fire eller bedre, resten får under karakter fire. Hypotesen vår er altså bekreftet. Denne undersøkelsen var oppdiktet, men hva tror du ville blitt resultatet om du gjorde en tilsvarende undersøkelse i din egen klasse? Prøv å lage en krysstabell med flere verdier på hver variabel og tolk den.
Oppgaver og fordypning
Flere eksempler





Les mer
Bøker:
- Hellevik, Ottar, Forskningsmetode i sosiologi og statsvitenskap, Universitetsforlaget 2003
- Kvale, Steinar, Det kvalitative forskningsintervju, Gyldendal Akademisk 2007
- Robson, Collin, Real world Research, Wiley-Blackwell 2002
- Ragin, Charles C. Constructing Social Research, Pine Forge Press, 1994
På internett
- Dette er Norge 2015 – SSBs store statistiske oversikt over det norske samfunnet i 2015 med informasjon om alt fra innvandring, familieforhold og dødsfall til arbeidskraft, databruk og landbruk. Alt du trenger på 48 sider.